Git : Git Snapshot으로 들어가보기
Git : Git Snapshot으로 들어가보기
저는 git을 쓰면서 git에 올린 데이터가 어떻게 관리되는지 , 어떻게 나오는지 확인한 적이 한번도 없었습니다. 그냥 명령어에 있는 대로 사용했는데 개인적으로 어떻게 돌아가는지도 모르면서 사용만 잘하는 걸 잘한다고 여기지 않기에 이 기회에? git이 어떻게 데이터를 관리하는지 정리했습니다.
git이 가진 특징
우선 들어가기 전에 git의 특징에 대해서 알아봅시다. 오늘 다룰 주제가 git의 특징 중 하나를 다룰 예정입니다! 😄 git은 아래 특징을 가지고 있습니다.
- 분산형 관리 시스템입니다.
- 각 작업자가 local에 clone한 repository는 commit histiory까지 포함된 실제 원본입니다.
- 따라서 svn과 달리 서버에 문제가 생겨도 크게 걱정할 필요가 없습니다.
- git은 local에서 모든 작업을 할 수 있습니다
- 인터넷이 없어도 가능합니다! 🧐
- 브랜치
- git은 브랜치를 이용해서 병렬 작업이 가능합니다.
- 실제로 git을 이용해서 작업할 경우 브랜치를 적극적으로 이용해서 협업할 것을 권장하고 있습니다.
git은 subversion과 무엇이 다를까요?
가장 큰 차이점은 svn은 중앙집중관리식, git은 분산관리식이라는 점입니다. 로컬 pc에서 svn으로 커밋하면 중앙 저장소에 바로 반영합니다. 반면 git은 commit을 하면 로컬 저장소에 반영되고 그 commit을 push하면 원격 저장소에 반영된다는 점입니다,
두번째는 버전을 관리하는 방식입니다. 두번째가 바로 오늘 다룰 주제입니다. 이 부분에서 svn은 시간의 흐름에 따라 생기는 버전을 델타로 관리하고, git은 스냅샷으로 관리합니다.
Delta And SnapShot
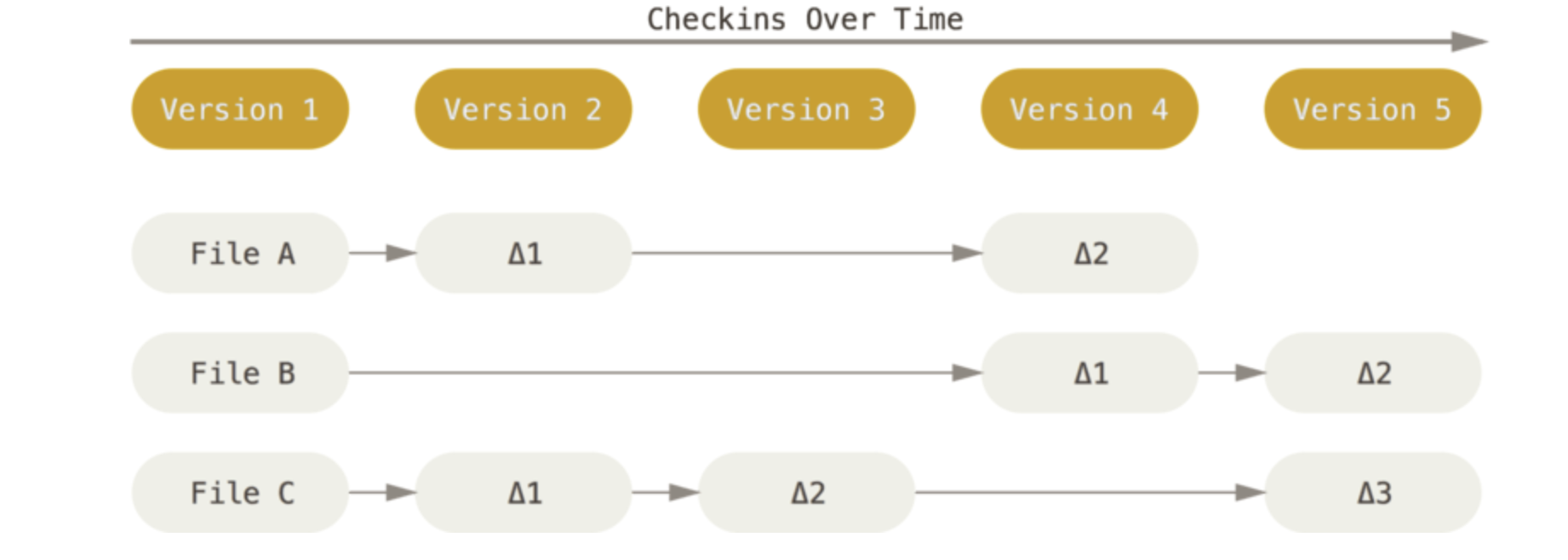
Delta는 각 버전간 개별 파일의 변경 사항이다.
Snapshot은 Revision의 대체 용어로 특정 시점의 항목 상태입니다. 쉽게 말하면 비디오 중간에 찍은 스크린샷 처럼 시간이 흐르면서 변하는 repository의 특정 시점의 파일과 폴더라고 할 수 있습니다, git에서 commit을 한다는 의미는 현재 workspace의 새로운 snapshot을 만든다는 의미입니다.
svn은 delta-baseed version control입니다. 버전마다 delta를 관리하여 원하는 버전을 가져올 때 델타를 적용해서 코드를 가져옵니다, 즉 각 버전에는 델타만 관리됩니다.
- 각 버전은 델타만 관리합니다. Version5를 가져온다면 각 delta를 적용해서 코드를 가져옵니다. 차지하는 용량은 적지만 히스토리가 길어질 경우 계산해야할 delta가 많아지므로 버전을 가져올 때 시간이 오래걸립니다.
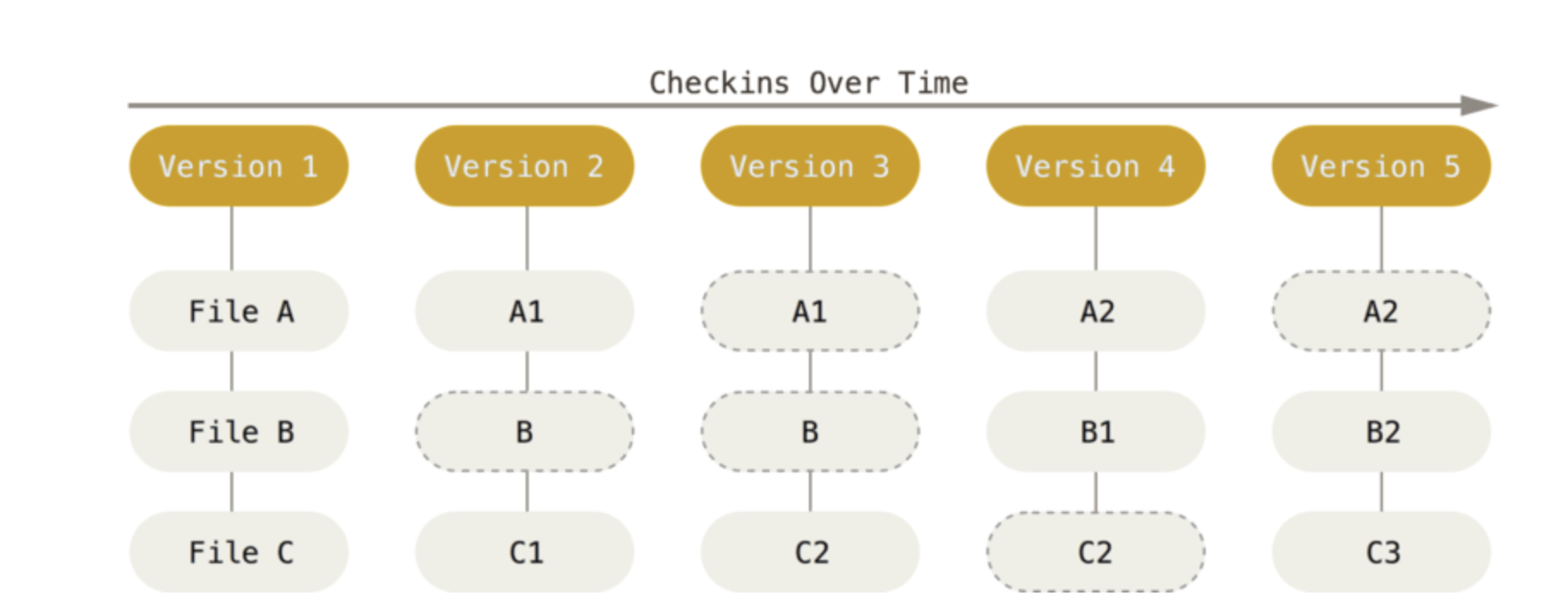
git은 SnapShot으로 관리합니다. 따라서 각 버전(commit)별로 스냅샷을 저장합니다. 따라서 하나의 git repository은 연속된 스냅샷이 연결된 구조입니다. 단 모든 파일을 스냅샷에 관리하지 않고 전 버전과 비교해서 변경되지 않는 파일은 이전 버전의 링크를 걸어둡니다.
- 각 버전별로 스냅샷을 만들어서 추적합니다. 차지하는 용량은 크지만 바로 버전을 가져오므로 각 버전별 전환이 매우 빠릅니다. 용량이 크다고 적었지만 git은 이를 영리하게 관리하고 있습니다.
- git은 때가되면 자동으로
auto gc명령어를 실행합니다.git gc명령어로 바로 실행할 수 있습니다. git은 스냅샷이 많거나 때가되면 Garbage를 collect하는데 이게 바로auto gc, 직접 실행할 경우git gc입니다. 헤드 커밋 스냅샷을 제외한 나머지 commit의 스냅샷을 삭제하고 delta를 저장합니다. 그래서 git은 snapshot 방식을 사용하지만 저장소 크기를 매우 작게 유지할 수 있습니다.
SnapShot tracking과 Delta tracking에 대해서는 아래 링크에서 확인하는걸 추천합니다.
git SnapShot 파해치기
git에 commit하면 새로운 snapshot을 만든다, 커밋에는 커밋 아이디가 붙는데 git은 SHA-1 hash를 사용해서 id를 부여합니다. 이 hash값은 git이 데이터를 저장하기 전에 체크섬을 구하고 그 체크섬으로 데이터를 관리하기 때문에 사용합니다. 이 값을 거의 유일한 값이기 때문에 보통 여덟 자나 열 자로만 줄여서 쓸 수 있습니다.
git은 이 SHA-1 해시값을 키로 해서 .git/objects/ 밑에 스냅샷을 만듭니다. 해시값의 마흔 자에서 앞 두 자는 폴더를 , 그 폴더 밑에 나머지 서른여덟자를 파일명으로 해서 소스코드나 이미지 등을 바이너리 형태로 압축해서 저장합니다.
스냅샷은 하나의 파일이 아니라 여러 파일의 집합을 스냅샷입니다. git log에서 확인 할 수 있는 커밋 해시값 중 앞 두자리로 만들어진 폴더가 해당 커밋의 metadata가 담긴 폴더입니다. metadata에는 해당 커밋의 정보( 커밋 메시지 , 작성자 , 부모 커밋 , 트리)를 확인 할 수 있습니다.
즉 하나의 스냅샷은 commit metadata와 소스 파일이나 이미지 파일 등을 저장한 blob로 구성됩니다. 실제 아래 사진을 통해서 확인해봅시다.
-
git init명령어로 git 저장소를 초기화 한 후a.txt에aaaaaaaaaa를 입력한 후git add --all,git commmit -m "first commit"을 입력합니다.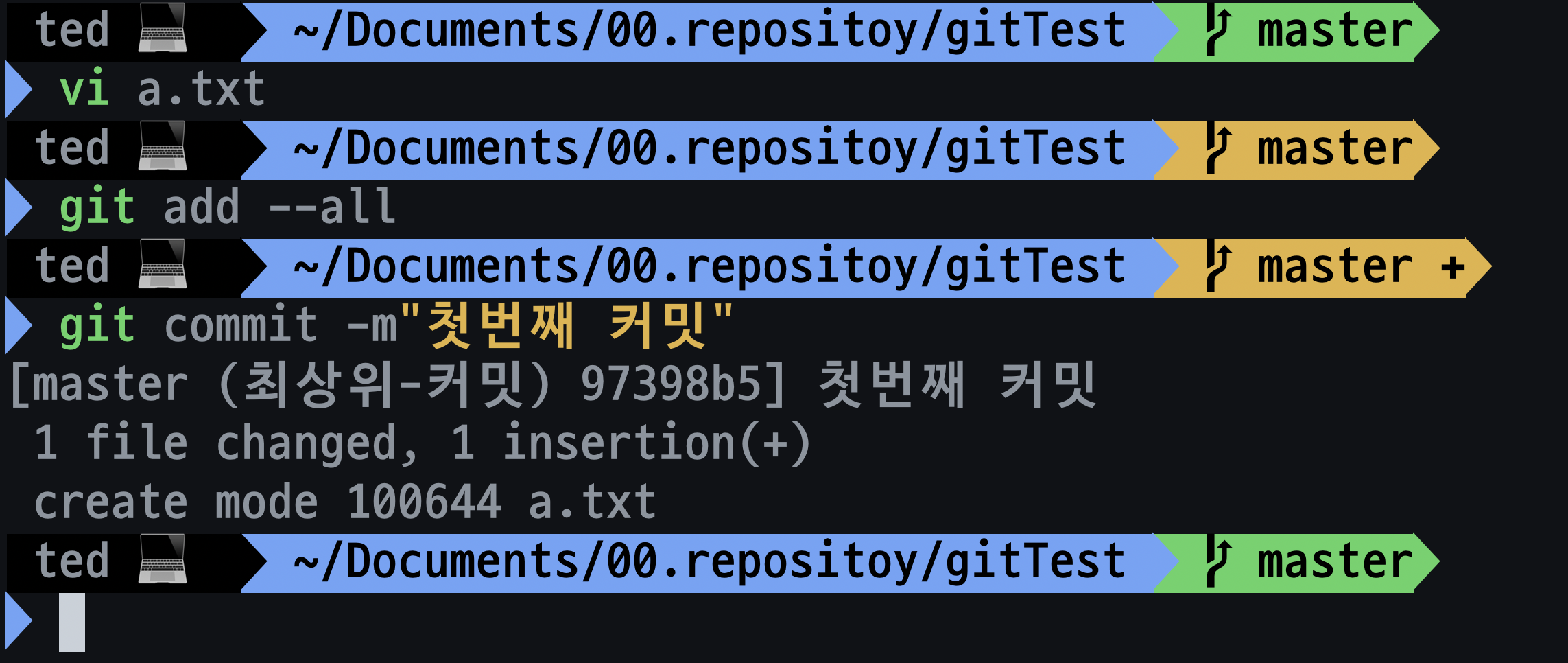
-
git log로 올라간 커밋 해시값을 찾습니다. 해당 해시값의 앞 두자리 폴더를.git/objects/에서 찾습니다. -
해당 파일에서
git cat-file -p {commit id}로 실제 object밑에 저장된 커밋 메타 데이터를 확인합니다.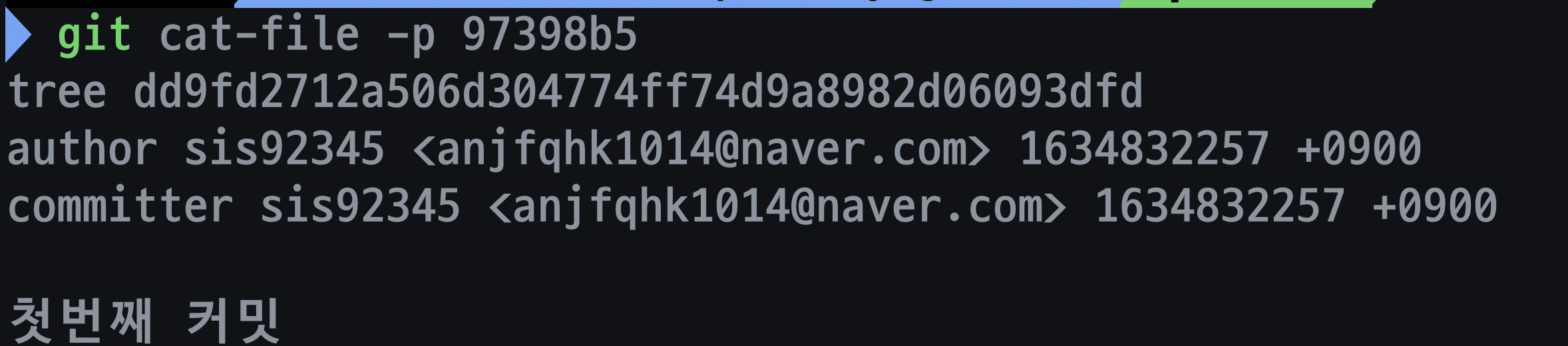
- commit metadata는 다음과 같이 구성되어 있습니다.
- tree : Unix의 directory , 따라서 하나의 트리는 여러개 파일을 가질 수 있다.
- blob : inode , 일반 파일
- parent : 부모 커밋
- author : 코드를 작성한 사람
- Commiter : 커밋한 사람
- tree : Unix의 directory , 따라서 하나의 트리는 여러개 파일을 가질 수 있다.
-
tree의 sha-1 포인터로 조회해봅시다.
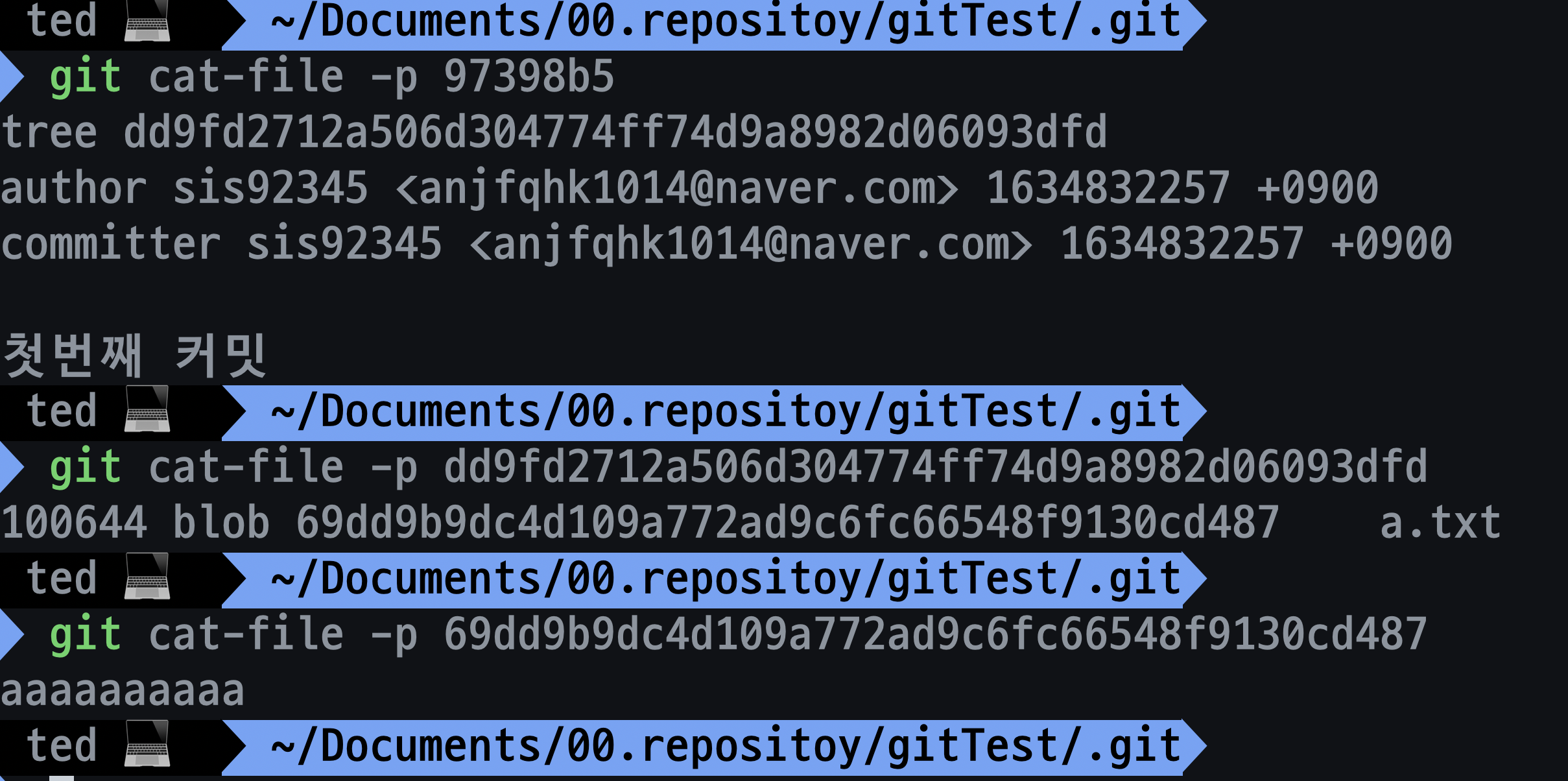
- 커밋한 a.txt를 확인할 수 있습니다.
- .git/object/97 : commit metadata
- .git/object/dd : commit 최상위 tree
- .git/object/69 : blob, 즉 a.txt의 바이너리 데이터를 합축한 파일
- 커밋한 a.txt를 확인할 수 있습니다.
-
이제 위에서 설명한
단 모든 파일을 스냅샷에 관리하지 않고 전 버전과 비교해서 변경되지 않는 파일은 이전 버전의 링크를 걸어둡니다.를 직접 확인해 봅시다. workspace에서b.txt를만든 후 커밋하고, 그 다음엔a.txt의 내용을 변경하고b.txt의 이름을bb.txt로 수정해서 커밋해봅시다. -
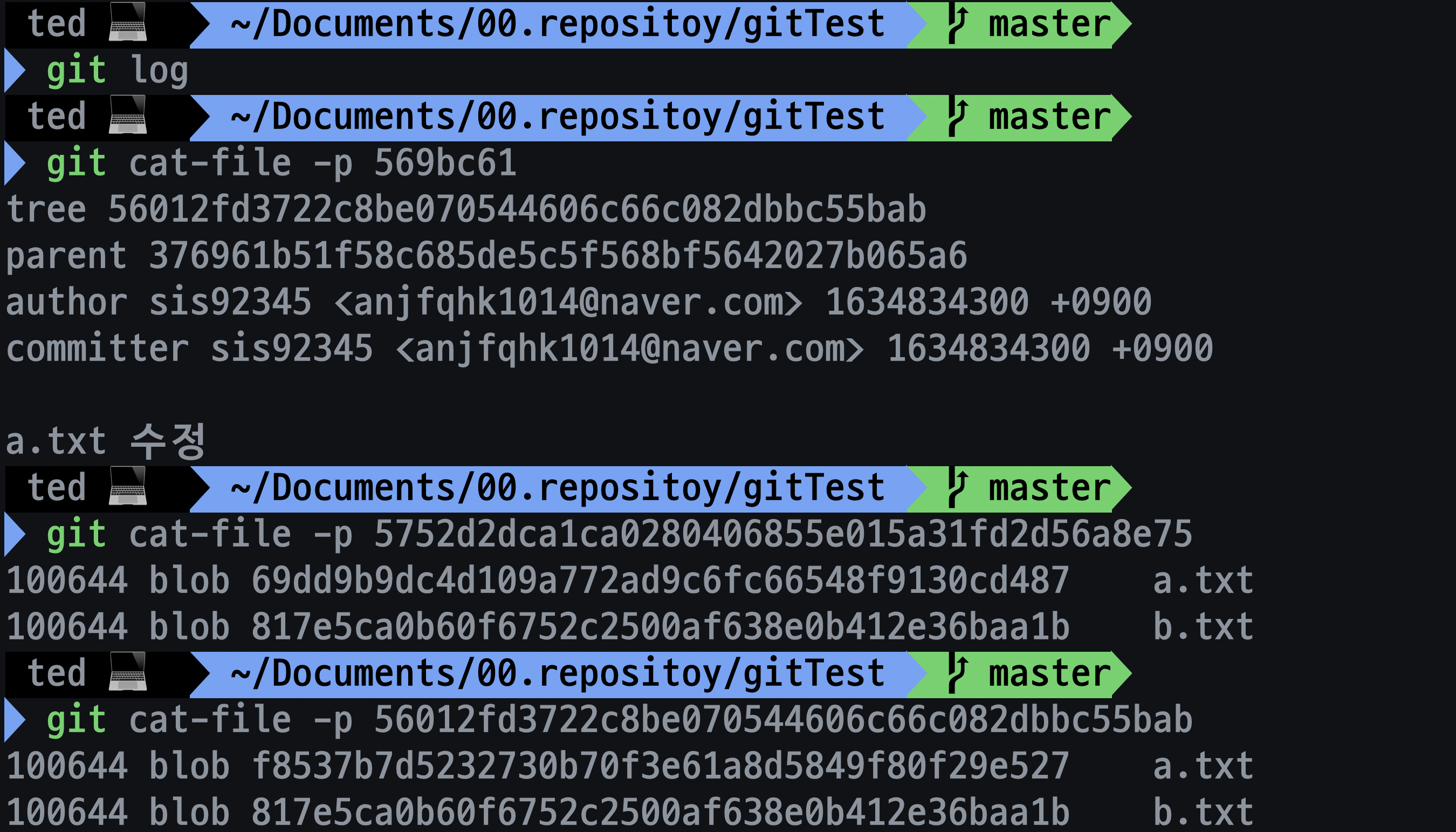
-
-
a.txt밑에 있는 파일이 두번째 커밋 , 맨 아래에 있는 파일이 세번째 커밋입니다.
-
파일 내용을 수정한
a.txt는 같은 다른 해시 값을 가지고 있습니다 즉 새로 스냅샷에 추가된 데이터입니다, -
b.txt의 경우 내용이 변경되었기 때문에 세번째 커밋의 해시값이 두번째 커밋과 동일한 것을 확인할 수 있습니다. 즉 앞서 말한대로 수정되지 않은 파일은 같은 해시값을 가지고 있는 것을 확인할 수 있습니다. -
내용은 같지만 이름이 변경되었을 경우에도 해시값은 동일합니다.

-